Title Text:”What? I can’t hear–” “What? I said, are you sure–” “CAN YOU PLEASE SPEAK–”
Origin:https://xkcd.com/2533/
https://www.explainxkcd.com/wiki/index.php/2533:_Slope_Hypothesis_Testing
斜率假设检验
注释:
图中的符号是统计学的符号,有兴趣的查一下p值。
http://xkcd.in/comic?lg=cn&id=2533
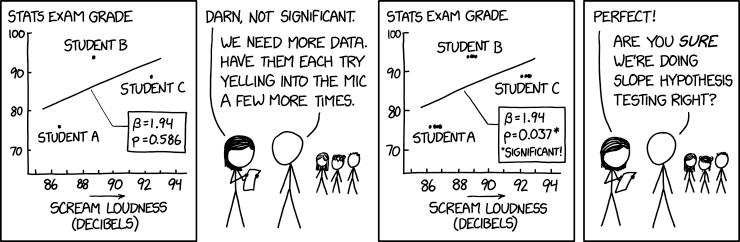
“斜率假设检验”是一种测试涉及散点图的假设的重要性的方法。
在这部漫画中,Cueball和梅根正在进行一项研究,将学生考试成绩与其尖叫声进行比较。学生 A 的成绩最差,尖叫声最轻,但学生 B 的成绩最好,学生 C 的尖叫声最大。已经绘制了一条趋势线,表明等级和交易量之间呈正相关……但 p 值非常高,表明对趋势的统计意义不大。P 值基于数据与趋势线的拟合程度以及采用了多少数据点;数据点越多,拟合越好,p 值越低,数据越显着。
梅根抱怨他们的结果无足轻重,因此 Cueball 建议让每个学生再对着麦克风尖叫几次。(从身后可以看到三个学生还在那里。三个学生看起来像小学生,其中一个是科学女郎。)
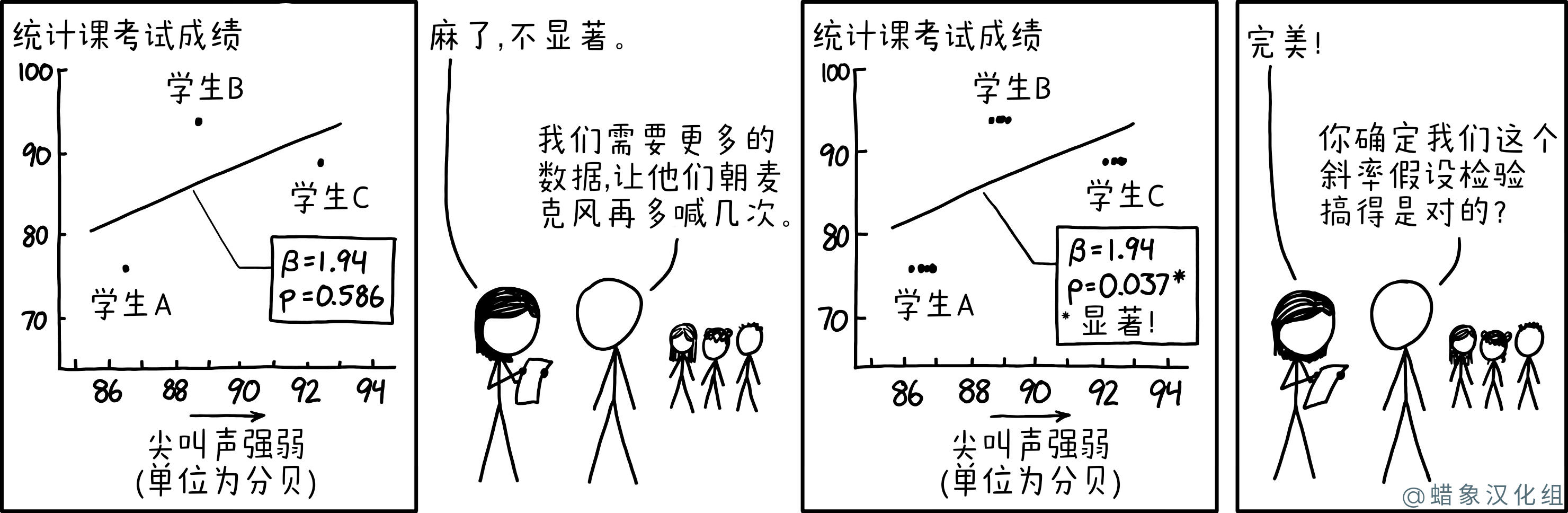
然而,让学生再次尖叫也无济于事,因为它只提供了更多关于尖叫的数据,而没有提供更多关于它与考试成绩的关系的数据,并且是一个关于今天可能在该领域进行的糟糕的统计计算的笑话。根据增加的测量次数重新计算 p 值不正确,而没有考虑观察值嵌套在学生体内这一事实。每个学生都有完全相同的测试分数(可能参考与以前相同的数据)并且音量范围也不会漂移很远(每个学生似乎都有一个相当一致且远离重叠的尖叫范围)。梅根对这些结果感到高兴,但 Cueball 迟到地意识到这种技术可能在科学上无效。Cueball 是正确的(假设他们使用的是简单的线性回归)。更合适的技术将解释数据的非独立性(多个数据点来自每个人)。此类技术的示例是多级建模和 Huber-White 稳健标准误差。
多次测量数据可以提高其准确性,但不会增加另一个指标的数据点数量,图表上的水平聚集点使这在视觉上更加清晰。收集数据测试更有效和科学正确的方法是测试其他学生并将他们的数字添加到现有数据中,而不是重复测试相同的三个学生。
常见的统计公式假设数据点在统计上是独立的,也就是说,一个点的测试分数和体积测量不会揭示其他点的任何信息。通过多次测量每个人的尖叫声,Cueball 和 Megan 违反了独立性假设(一个人的尖叫声不太可能独立于一次尖叫声到下一次尖叫声)并使他们的显着性计算无效。这是伪复制的一个例子。此外,Megan 和 Cueball 未能为每个学生获得新的考试成绩,这将进一步限制他们的统计选择。
他们实验的另一个奇怪的方面是在典型的线性回归过程中获得的 p 值假设 y 值存在不确定性,但 x 值是完全已知的,而在这个实验中,它们减少了 x 值的不确定性他们的数据,而没有做任何事情来提高对 y 值的了解。
此外,即使新数据在统计上是独立的,这似乎仍然是“p-hacking”的经典示例,即添加新数据直到获得具有统计显着性的 p 值。
在当前的 AI 中,正在推动“少量学习”,其中仅使用少数数据项来形成结论,而不是通常的数百万个数据项。这部漫画展示了在不深入了解这些方法的情况下使用此类方法的危险。
此外,一些研究中的一个共同主题是发现无法独立繁殖的相关性。这是因为样本太少的随机性会产生明显的相关性,而兰德尔一再为这个有希望的错误制作漫画。
在标题文本中,Megan 和 Cueball 试图互相大喊大叫,要求对方大声说出来,这样他们才能被听到,大概是因为他们在大喊大叫实验中遇到了问题。或者他们可能因为在统计考试中成绩不佳而无法听清说话。


